Leetcode
1. Two Sum: find a pair with specific sum
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
numMap = {}
n = len(nums)
# Build the hash table
for i in range(n):
numMap[nums[i]] = i
# Find the complement
for i in range(n):
complement = target - nums[i]
if complement in numMap and numMap[complement] != i:
return [i, numMap[complement]]
return [] # No solution foundYou might wonder how does the code deals with duplicates.
As you can see, in the iteration of building the hash table, always the latter(with bigger index) will be saved in the hash table. In the latter iteration finding the complement, the former one(with smaller index) always goes through the iteration earlier, so the [i, numMap[complement]] can return two different indexes, carrying duplicate values.
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
numMap = {}
n = len(nums)
for i in range(n):
complement = target - nums[i]
if complement in numMap:
return [numMap[complement], i]
numMap[nums[i]] = i
return [] # No solution found
use stack
3. Palindrome Number
Make sure that you minimize the number of iterations.
4. Binary Search
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid # Target found, return its index
elif arr[mid] < target:
left = mid + 1 # Search the right half
else:
right = mid - 1 # Search the left half
return -1 # Target not found
Key is if statement that splits into three conditions: == target, < target, > target
5. Merge Sorted arrays
Consider starting iterations from the end(backwards iteration)
6. Tree Traversal
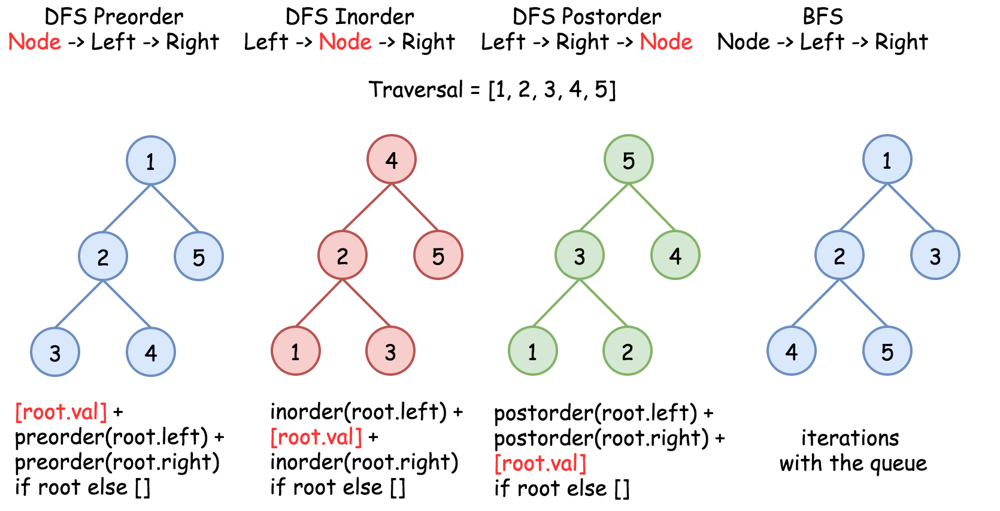
DFS: uses recursion, can also use Stack
PreOrder: Node->Left->Right, Pre because the node comes before the left and right
InOrder: Left->Node->Right , In because the node comes 'in' middle of the left and right
PostOrder: Left->Right->Node , Post because the node comes after the left and right
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
ans = []
stack = [root]
while (stack):
current = stack.pop()
if current:
ans.append(current)
stack.append(current.right)
stack.append(current.left)
return ans
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
ans = []
stack = []
current = root
while (current or stack):
while(current != None):
stack.append(current)
current = current.left
current = stack.pop()
ans.append(current.val)
current = current.right
return ans
class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
ans = []
stack = []
last_visited = None
current = root
while stack or current:
if current:
stack.append(current)
current = current.left # Move left first
else:
peek = stack[-1]
if peek.right and last_visited != peek.right:
current = peek.right # Move to right child
else:
ans.append(peek.val) # Visit node
last_visited = stack.pop() # Mark as visited
return ans
In the stack approach, the key is the inner loop that appends appends current and current.left
BFS: no recursion, with iteration using Queue
The recursive codes are 'DFS'. It call the codes recursion that would solve the first code always first. For example, let's suppose that we have a tree like the below
A
/ \
B C
/ \ \
D E F
def dfs(root, depth):
if not root: return depth
return max(dfs(root.left, depth + 1), dfs(root.right, depth + 1))
The compiler would not call B -> C. Because regarding, max(dfs(B, depth + 1), dfs(C, depth + 1)). The max(dfs(B, depth + 1) must be resolved before dfs(C, depth + 1)). Thus, the compiler calls max(dfs(D, depth + 1), dfs(E, depth + 1)). Thus, it would run as
A -> B -> D -> E -> C -> F
,which is DFS.
141. Linked List Cycle
Floyd's Cycle Finding Algorithm(a.k.a. "Hare-and-Tortoise")
1. Two Pointer(fast & slow) is initialized to point head.
2. Fast traverses fast with Fast = Fast.next.next
Slow traverses slow with Slow = Slow.next
3. We can conclude that cycle exists if Fast == Slow at some moment.
160. Intersection of Two Linked Lists
O(m + n) time and O(1) memory Solution1. Two pointer(a, b) is initialized to the head of each lists
2. Two pointer(a, b) traverses each list at same speed
3. If a pointer reaches end of the list, it goes to the head of the other list(i.e. if reaches the end of list A, goes to the head of list B)
4. 1. If a == b != null at some moment, it is the intersection of two lists
2. If a == b == null at some moment, there's no intersection
This algorithm meets either of 4.1. or 4.2. while it traverses two lists(A -> B -> end). Thus it is O(m + n)
Dynamic programming
1. Top-Down
Basically based on recursion. Thus, it might not use stored values. Top-Down means that it starts from the big problem, and the big problem calls small problems through recursively.
Recursion:
if terminate condition
elif dp exists
else recursion(...)
2. Bottom-Up
Basically based on iteration. Thus, it uses all the stored values, since the stored values are required for the next iteration. It starts from the small problems, and builds the solution of bigger problems.
Jump Game
bool canJump(int A[], int n)
int i = 0;
for (int reach = 0; i < n && i <= reach; ++i)
reach = max(i + A[i], reach);
return i == n;
}
Difference of 'is' and '=='
0 is False => False, is should be exactly the same
0 == False => True
댓글
댓글 쓰기